

An essential function of data catalogs is to help large enterprises with their significant data initiatives figure out what data they have available. Most modern Data Catalog Software heavily relies on artificial intelligence (AI) and machine learning (ML). ML in data catalogs can enable some basic analytics and provide other types of recommendations, but it also often provides a score that indicates how reliable the data is.
Thanks to data catalogs, a company may have a single picture of all its data assets. Since the early days of relational databases, when IT teams needed to monitor the linking, joining, and transformation of data sets across SQL tables, the concept of a catalog has existed.
Data lakes, data warehouses, NoSQL databases, cloud object storage, and other data stores are among the many data sources from which modern data catalog technologies inventory data and gather information about it.
Some Famous Data Catalog Software
1. Alation Data Catalog
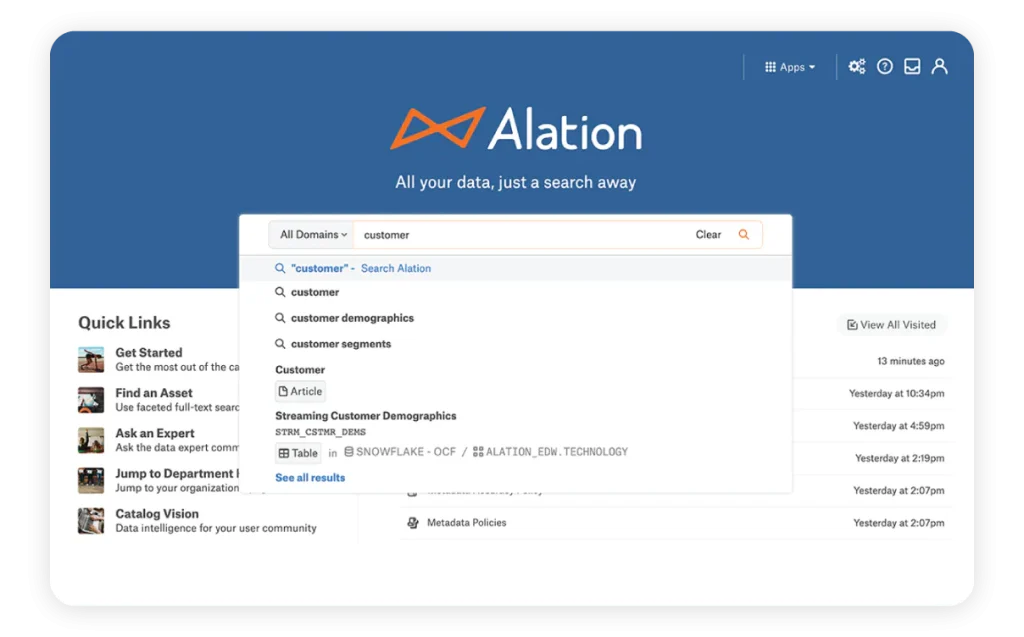
Alation was established in 2012, and its first products were released in 2015. Utilizing artificial intelligence (AI), machine learning, automation, and natural language processing, the company’s flagship data catalog software streamlines data discovery, generates business glossaries automatically and powers its central Behavioral Analysis Engine, which examines data usage patterns to streamline data governance, stewardship, and query optimization.
The engine creates popularity rankings using suggestions and other insights by indexing several data sources and using pattern recognition. Altogether, Alation’s capabilities are billed as a “data intelligence” platform; it also provides a data governance application.
Alation Data Catalog is equipped with a number of collaborative capabilities and guided navigation options. It may, for instance, automatically locate data stewards or other subject matter experts to respond to inquiries about data sets.
Users can also generate searchable chats and wiki entries. Users have the option to subscribe and get automatic updates whenever new articles or data sets are posted.
Features:
- AI/Machine Learning.
- Access Controls/Permissions.
- Activity Dashboard.
- Activity Tracking.
- Audit Management.
- Audit Trail.
- Automatic Backup.
- Behavior Analytics.
Pricing:
- Free trial available.
- Full version: Contact sales for custom pricing.
2. Alex Augmented Data Catalog
Founded in 2016, Alex Solutions is a more recent supplier of metadata management and Data Catalog Software. The business designed its data catalog software with AI and machine learning methods in mind.
Alex Augmented Data Catalog supports a variety of structured, semi-structured, and unstructured data formats and aids in automating the process of locating data assets and then putting them into a consolidated catalog. Additionally, the platform has a number of collaborative tools for sharing and curating data, among other things.
Furthermore, Alex uses the data catalog tool to automate a number of data governance and data quality tasks. Data governance administrators, for instance, may monitor data pipeline operations, designate data stewards, and establish rules all from a single interface.
Features:
- Automated Cross-Application Data Lineage.
- 100% Personalization.
- End-To-End Solution.
- Real Automation.
- Technology Agnostic.
- Metadata Management Service.
- Data Centric Solution.
- Data Governance.
- Numerous integrations.
Pricing:
- Free demo available.
- Contact Alex for pricing.
3. Aginity
One of the top Data Catalog Tools is Aginity. The explanations range from its SQL friendliness and easily navigable product ecosystem to its potential for on-demand service scaling. It archives all of the company’s data as well as the mathematics used to provide analytics.
For this reason, Aginity is regarded as the only comprehensive analytics management product in the world that automatically facilitates improved communication between business analysts and data engineers. Its readily available data governance and data cleaning features are another reason for its popularity.
Features:
- Data management to analytics management.
- Extensive business use cases.
- Smooth Interfaces with Top Tools.
- Easily navigable interface for marketers and developers.
- One True Source for All of Your Content.
- Simple Editing for Non-Technical Users.
Pricing:
- Aginity Pro: $150/ user/ year.
- Aginity Premium: $500/ user/ year.
- Aginity Enterprise: Contact Aginity.
4. AWS Glue Data Catalog
The permanent metadata store of AWS Glue, a fully managed extract, transform, and load (ETL) service provided by AWS, is called the AWS Glue Data Catalog. When data management teams build data warehouses or data lakes on the AWS cloud platform, they may utilize the data catalog to store, annotate, and distribute information for use in ETL integration operations.
It works with the megastore repository in Apache Hive, a well-known open-source data warehousing program, and enables features comparable to that. Organizations may include the AWS data catalog as an external Hive data megastore.
With their AWS Identity and Access Management (IAM) credentials, users may provide access to the AWS Glue Data Catalog to other users inside their company. By monitoring modifications to schemas and data access rules, the data catalog tool aids in the enforcement of data governance regulations.
It also supports data operations across several AWS services, such as Amazon EMR, AWS Lake Formation, Amazon Athena, Amazon Redshift, and more. Additionally, corporate data catalogs in Amazon DataZone—a different data management service with a preview release planned for early 2023—can be filled using the AWS Glue Data Catalog.
Features:
- Automatic schema discovery.
- Manage and enforce schemas for data streams.
- Automatically scale based on workload.
- Built-in machine learning (ML).
- Edit, debug, and test ETL code with developer endpoints.
- Scale existing Python code.
- Define, detect, and remediate sensitive data.
- Built-in job notebooks.
- Build complex ETL pipelines.
Pricing:
- Free trial available.
- ETL Jobs and Development Endpoints: $0.44.
- Data catalog storage and requests: $1/ month.
- Crawlers and DataBrew Interactive sessions: $0.44.
- DataBrew Job: $0.48.
5. Amundsen Lyft
Amundsen is a data discovery and metadata engine that bears the name of the Norwegian explorer Ronald Amundsen. The Lyft engineering team created the program to solve everyday problems.
Amundsen helped Lyft’s data teams increase productivity by at least 20%. Generally speaking, Amundsen was designed to provide a consolidated data cataloging repository from many data sources and to produce insight into the metadata-driven evolution of certain activities.
Features:
- Easy data discovery.
- Data governance.
- Data lineage.
- Open source.
- See automated and curated metadata.
- Share context with colleagues.
- Automated Metadata.
- Intuitive & Pluggable.
Pricing:
- Free trial available.
- Contact Amundsen for a quotation.
6. data.world

A cloud-based company called ‘data.world’ is the name of the Data Catalog Software used with the present data stack. With the data, users may do in-depth searches utilizing a variety of filters, logical operators, categories, and custom metadata in the ‘data.world’ Search Engine.
Its distinctive service architecture offers a flexible answer to all of your demands for governance, analysis, and data storage. In addition to being certified B, ‘data.world’ positions itself openly as a Public Benefit Corporation.
Features:
- Complex search option.
- Sensitive Data Discovery.
- Multiple variants of interest.
- Unified body of knowledge.
- Easy to access.
- Master Data Management.
- Information Governance.
- Data Capture.
- Customer Data.
- Data Migration.
- Data Security.
- Data Integration.
- Data Analysis.
Pricing:
- Free trial available.
- Starting Price: $12 per month.
7. Boomi Data Catalog and Preparation
Boomi Data Catalog and Preparation is a component of AtomSphere Platform, a suite of technologies that facilitates master data management, data integration, and other activities. It integrates data preparation features with a data catalog.
Using the catalog, businesses may compile a business dictionary of information for tracking data sets, processing tasks, and workflow plans. Data can then be automatically cleaned, enriched, normalized, and transformed by running a data prep recommendation engine.
Features:
- Boomi platform.
- Atoms, Molecules, and Atom Clouds.
- Integration.
- Platform API and Partner API.
- Connectivity development.
- Master Data Hub.
- B2B/EDI Management.
- API Management.
Pricing:
- Free trial available.
- Professional: $2,000/ month.
- Pro Plus: $4,000/ month.
- Enterprise: $8,000/ month.
- Enterprise Plus: Contact Boomi.
8. Collibra Data Catalog
Founded in 2008, Collibra provides a Data Intelligence Cloud platform based on Collibra Data Catalog. With the use of a patented machine learning algorithm, its data catalog capabilities provide a wide range of automated features for data search and categorization, data curation that is fueled by machine learning, and data lineage.
Additionally, the data catalog tool provides graph-based metadata management strategies that aid in giving users access to data lineage and quality information.
Features:
- Sensitive Data Compliance.
- Training and Guidelines.
- Policy Enforcement.
- Compliance Monitoring.
- Business Glossary.
- Data Discovery.
- Data Profiling.
- Reporting and Visualization.
- Data Lineage.
Pricing:
- Free trial available.
- Annual package: $150,000.
9. Google Cloud Data Catalog
One of the completely managed Data Catalog Tools for finding data across on-premises and cloud data sources is Google Cloud Data Catalog. It is intended to allow data professionals and business users to categorize data at scale and do natural language searches inside a catalog.
The tool comes pre-integrated with Google Cloud Storage, BigQuery, Pub/Sub, and Dataproc Metastore data services. In order to enhance data security and compliance management as part of data governance efforts, it is also connected with the company’s IAM and Cloud Data Loss Prevention services.
Because the data catalog software is offered as a serverless service, customers do not need to worry about setting up or managing infrastructure. Through the user interface (UI) of Google’s Dataplex data fabric environment, a CLI, sets of APIs, and client libraries, it facilitates the categorization of data assets and provides access to additional functionality.
Technical and commercial information, including tags and tag templates, may both be stored by the tool. Custom metadata types and file set schemas from the Cloud Storage service may also be saved.
Features:
- User Access Management.
- Dynamic Data Masking.
- Data Lineage.
- Search.
- Data Quality and Cleansing.
- Commenting.
- Profiling and Classification.
- Metadata Management.
- Automatic Data Cleansing.
Pricing:
- Free Up to 1 MiB.
- Over 1 MiB: $100 per GiB per month.
Benefits of Using Data Catalog Tools
Data Catalog Software may take many different forms. However, they often provide you with the same set of benefits, such as:
- Excellent catalog with all of your information.
- Tracking of data transit between various data formats.
- Find the problems in your data flow and fix them.
- Capability for managing sensitive data.
- There is a meager chance of data breaches.
- Features of machine learning to facilitate smooth, extensive data management.
FAQ
Q: Can I use Data Catalog Software for free?
A: Not many companies offer a free version. But you can have a free trial.
Q: What kind of data is most suited for creating a data catalog?
A: Metadata, or the descriptive information about data needed to build the data inventory, is what powers data catalogs. Additionally, the underlying metadata gives catalog users insight into data assets, enabling them to comprehend the data accessible in IT systems better and determine whether or not it meets their requirements.
Q: What does a data catalog need to have?
A: Traditional tables are not the only data asset types that a contemporary data catalog must support and manage. This covers features, Jupyter notebooks, predictive models, code snippets, SQL queries, and business intelligence (BI) dashboards.